















authors and affiliations
The study of computer chess is as old as computer science itself. Charles Babbage, Alan Turing, Claude Shannon, and John von Neumann devised hardware, algorithms, and theory to analyze and play the game of chess. Chess subsequently became a grand challenge task for a generation of artificial intelligence researchers, culminating in high-performance computer chess programs that play at a superhuman level (1, 2). However, these systems are highly tuned to their domain and cannot be generalized to other games without substantial human effort, whereas general game-playing systems (3, 4) remain comparatively weak.
A long-standing ambition of artificial intelligence has been to create programs that can instead learn for themselves from first principles (5, 6). Recently, the AlphaGo Zero algorithm achieved superhuman performance in the game of Go by representing Go knowledge with the use of deep convolutional neural networks (7, 8), trained solely by reinforcement learning from games of self-play (9). In this paper, we introduce AlphaZero, a more generic version of the AlphaGo Zero algorithm that accommodates, without special casing, a broader class of game rules. We apply AlphaZero to the games of chess and shogi, as well as Go, by using the same algorithm and network architecture for all three games. Our results demonstrate that a general-purpose reinforcement learning algorithm can learn, tabula rasa—without domain-specific human knowledge or data, as evidenced by the same algorithm succeeding in multiple domains—superhuman performance across multiple challenging games.
A landmark for artificial intelligence was achieved in 1997 when Deep Blue defeated the human world chess champion (1). Computer chess programs continued to progress steadily beyond human level in the following two decades. These programs evaluate positions by using handcrafted features and carefully tuned weights, constructed by strong human players and programmers, combined with a high-performance alpha-beta search that expands a vast search tree by using a large number of clever heuristics and domain-specific adaptations. In (10) we describe these augmentations, focusing on the 2016 Top Chess Engine Championship (TCEC) season 9 world champion Stockfish (11); other strong chess programs, including Deep Blue, use very similar architectures (1, 12).
In terms of game tree complexity, shogi is a substantially harder game than chess (13, 14): It is played on a larger board with a wider variety of pieces; any captured opponent piece switches sides and may subsequently be dropped anywhere on the board. The strongest shogi programs, such as the 2017 Computer Shogi Association (CSA) world champion Elmo, have only recently defeated human champions (15). These programs use an algorithm similar to those used by computer chess programs, again based on a highly optimized alpha-beta search engine with many domain-specific adaptations.
AlphaZero replaces the handcrafted knowledge and domain-specific augmentations used in traditional game-playing programs with deep neural networks, a general-purpose reinforcement learning algorithm, and a general-purpose tree search algorithm.
Instead of a handcrafted evaluation function and move-ordering heuristics, AlphaZero uses a deep neural network (p, v) = fθ(s) with parameters θ. This neural network fθ(s) takes the board position sas an input and outputs a vector of move probabilities p with components pa = Pr(a|s) for each action a and a scalar value v estimating the expected outcome z of the game from position s,  . AlphaZero learns these move probabilities and value estimates entirely from self-play; these are then used to guide its search in future games.
. AlphaZero learns these move probabilities and value estimates entirely from self-play; these are then used to guide its search in future games.
Instead of an alpha-beta search with domain-specific enhancements, AlphaZero uses a general-purpose Monte Carlo tree search (MCTS) algorithm. Each search consists of a series of simulated games of self-play that traverse a tree from root state sroot until a leaf state is reached. Each simulation proceeds by selecting in each state s a move a with low visit count (not previously frequently explored), high move probability, and high value (averaged over the leaf states of simulations that selected a from s) according to the current neural network fθ. The search returns a vector π representing a probability distribution over moves, πa = Pr(a|sroot).
The parameters θ of the deep neural network in AlphaZero are trained by reinforcement learning from self-play games, starting from randomly initialized parameters θ. Each game is played by running an MCTS from the current position sroot = st at turn t and then selecting a move, at ~ πt, either proportionally (for exploration) or greedily (for exploitation) with respect to the visit counts at the root state. At the end of the game, the terminal position sT is scored according to the rules of the game to compute the game outcome z: −1 for a loss, 0 for a draw, and +1 for a win. The neural network parameters θ are updated to minimize the error between the predicted outcome vtand the game outcome z and to maximize the similarity of the policy vector pt to the search probabilities πt. Specifically, the parameters θ are adjusted by gradient descent on a loss function lthat sums over mean-squared error and cross-entropy losses (1)where c is a parameter controlling the level of L2 weight regularization. The updated parameters are used in subsequent games of self-play.
(1)where c is a parameter controlling the level of L2 weight regularization. The updated parameters are used in subsequent games of self-play.
The AlphaZero algorithm described in this paper [see (10) for the pseudocode] differs from the original AlphaGo Zero algorithm in several respects.
AlphaGo Zero estimated and optimized the probability of winning, exploiting the fact that Go games have a binary win or loss outcome. However, both chess and shogi may end in drawn outcomes; it is believed that the optimal solution to chess is a draw (16–18). AlphaZero instead estimates and optimizes the expected outcome.
The rules of Go are invariant to rotation and reflection. This fact was exploited in AlphaGo and AlphaGo Zero in two ways. First, training data were augmented by generating eight symmetries for each position. Second, during MCTS, board positions were transformed by using a randomly selected rotation or reflection before being evaluated by the neural network, so that the Monte Carlo evaluation was averaged over different biases. To accommodate a broader class of games, AlphaZero does not assume symmetry; the rules of chess and shogi are asymmetric (e.g., pawns only move forward, and castling is different on kingside and queenside). AlphaZero does not augment the training data and does not transform the board position during MCTS.
In AlphaGo Zero, self-play games were generated by the best player from all previous iterations. After each iteration of training, the performance of the new player was measured against the best player; if the new player won by a margin of 55%, then it replaced the best player. By contrast, AlphaZero simply maintains a single neural network that is updated continually rather than waiting for an iteration to complete. Self-play games are always generated by using the latest parameters for this neural network.
As in AlphaGo Zero, the board state is encoded by spatial planes based only on the basic rules for each game. The actions are encoded by either spatial planes or a flat vector, again based only on the basic rules for each game (10).
AlphaGo Zero used a convolutional neural network architecture that is particularly well-suited to Go: The rules of the game are translationally invariant (matching the weight-sharing structure of convolutional networks) and are defined in terms of liberties corresponding to the adjacencies between points on the board (matching the local structure of convolutional networks). By contrast, the rules of chess and shogi are position dependent (e.g., pawns may move two steps forward from the second rank and promote on the eighth rank) and include long-range interactions (e.g., the queen may traverse the board in one move). Despite these differences, AlphaZero uses the same convolutional network architecture as AlphaGo Zero for chess, shogi, and Go.
The hyperparameters of AlphaGo Zero were tuned by Bayesian optimization. In AlphaZero, we reuse the same hyperparameters, algorithm settings, and network architecture for all games without game-specific tuning. The only exceptions are the exploration noise and the learning rate schedule [see (10) for further details].
We trained separate instances of AlphaZero for chess, shogi, and Go. Training proceeded for 700,000 steps (in mini-batches of 4096 training positions) starting from randomly initialized parameters. During training only, 5000 first-generation tensor processing units (TPUs) (19) were used to generate self-play games, and 16 second-generation TPUs were used to train the neural networks. Training lasted for approximately 9 hours in chess, 12 hours in shogi, and 13 days in Go (see table S3) (20). Further details of the training procedure are provided in (10).
Figure 1 shows the performance of AlphaZero during self-play reinforcement learning, as a function of training steps, on an Elo (21) scale (22). In chess, AlphaZero first outperformed Stockfish after just 4 hours (300,000 steps); in shogi, AlphaZero first outperformed Elmo after 2 hours (110,000 steps); and in Go, AlphaZero first outperformed AlphaGo Lee (9) after 30 hours (74,000 steps). The training algorithm achieved similar performance in all independent runs (see fig. S3), suggesting that the high performance of AlphaZero’s training algorithm is repeatable.

Fig. 1Training AlphaZero for 700,000 steps.
Elo ratings were computed from games between different players where each player was given 1 s per move. (A) Performance of AlphaZero in chess compared with the 2016 TCEC world champion program Stockfish. (B) Performance of AlphaZero in shogi compared with the 2017 CSA world champion program Elmo. (C) Performance of AlphaZero in Go compared with AlphaGo Lee and AlphaGo Zero (20 blocks over 3 days).
We evaluated the fully trained instances of AlphaZero against Stockfish, Elmo, and the previous version of AlphaGo Zero in chess, shogi, and Go, respectively. Each program was run on the hardware for which it was designed (23): Stockfish and Elmo used 44 central processing unit (CPU) cores (as in the TCEC world championship), whereas AlphaZero and AlphaGo Zero used a single machine with four first-generation TPUs and 44 CPU cores (24). The chess match was played against the 2016 TCEC (season 9) world champion Stockfish [see (10) for details]. The shogi match was played against the 2017 CSA world champion version of Elmo (10). The Go match was played against the previously published version of AlphaGo Zero [also trained for 700,000 steps (25)]. All matches were played by using time controls of 3 hours per game, plus an additional 15 s for each move.
In Go, AlphaZero defeated AlphaGo Zero (9), winning 61% of games. This demonstrates that a general approach can recover the performance of an algorithm that exploited board symmetries to generate eight times as much data (see fig. S1).
In chess, AlphaZero defeated Stockfish, winning 155 games and losing 6 games out of 1000 (Fig. 2). To verify the robustness of AlphaZero, we played additional matches that started from common human openings (Fig. 3). AlphaZero defeated Stockfish in each opening, suggesting that AlphaZero has mastered a wide spectrum of chess play. The frequency plots in Fig. 3 and the time line in fig. S2 show that common human openings were independently discovered and played frequently by AlphaZero during self-play training. We also played a match that started from the set of opening positions used in the 2016 TCEC world championship; AlphaZero won convincingly in this match, too (26) (fig. S4). We played additional matches against the most recent development version of Stockfish (27) and a variant of Stockfish that uses a strong opening book (28). AlphaZero won all matches by a large margin (Fig. 2).

Fig. 2Comparison with specialized programs.
(A) Tournament evaluation of AlphaZero in chess, shogi, and Go in matches against, respectively, Stockfish, Elmo, and the previously published version of AlphaGo Zero (AG0) that was trained for 3 days. In the top bar, AlphaZero plays white; in the bottom bar, AlphaZero plays black. Each bar shows the results from AlphaZero’s perspective: win (W; green), draw (D; gray), or loss (L; red). (B) Scalability of AlphaZero with thinking time compared with Stockfish and Elmo. Stockfish and Elmo always receive full time (3 hours per game plus 15 s per move); time for AlphaZero is scaled down as indicated. (C) Extra evaluations of AlphaZero in chess against the most recent version of Stockfish at the time of writing (27) and against Stockfish with a strong opening book (28). Extra evaluations of AlphaZero in shogi were carried out against another strong shogi program, Aperyqhapaq (29), at full time controls and against Elmo under 2017 CSA world championship time controls (10 min per game and 10 s per move). (D) Average result of chess matches starting from different opening positions, either common human positions (see also Fig. 3) or the 2016 TCEC world championship opening positions (see also fig. S4), and average result of shogi matches starting from common human positions (see also Fig. 3). CSA world championship games start from the initial board position. Match conditions are summarized in tables S8 and S9.

Fig. 3Matches starting from the most popular human openings.
AlphaZero plays against (A) Stockfish in chess and (B) Elmo in shogi. In the left bar, AlphaZero plays white, starting from the given position; in the right bar, AlphaZero plays black. Each bar shows the results from AlphaZero’s perspective: win (green), draw (gray), or loss (red). The percentage frequency of self-play training games in which this opening was selected by AlphaZero is plotted against the duration of training, in hours.
Table S6 shows 20 chess games played by AlphaZero in its matches against Stockfish. In several games, AlphaZero sacrificed pieces for long-term strategic advantage, suggesting that it has a more fluid, context-dependent positional evaluation than the rule-based evaluations used by previous chess programs.
In shogi, AlphaZero defeated Elmo, winning 98.2% of games when playing black and 91.2% overall. We also played a match under the faster time controls used in the 2017 CSA world championship and against another state-of-the-art shogi program (29); AlphaZero again won both matches by a wide margin (Fig. 2).
Table S7 shows 10 shogi games played by AlphaZero in its matches against Elmo. The frequency plots in Fig. 3 and the time line in fig. S2 show that AlphaZero frequently plays one of the two most common human openings but rarely plays the second, deviating on the very first move.
AlphaZero searches just 60,000 positions per second in chess and shogi, compared with 60 million for Stockfish and 25 million for Elmo (table S4). AlphaZero may compensate for the lower number of evaluations by using its deep neural network to focus much more selectively on the most promising variations (Fig. 4 provides an example from the match against Stockfish)—arguably a more humanlike approach to searching, as originally proposed by Shannon (30). AlphaZero also defeated Stockfish when given  as much thinking time as its opponent (i.e., searching
as much thinking time as its opponent (i.e., searching  as many positions) and won 46% of games against Elmo when given
as many positions) and won 46% of games against Elmo when given  as much time (i.e., searching
as much time (i.e., searching  as many positions) (Fig. 2). The high performance of AlphaZero with the use of MCTS calls into question the widely held belief (31, 32) that alpha-beta search is inherently superior in these domains.
as many positions) (Fig. 2). The high performance of AlphaZero with the use of MCTS calls into question the widely held belief (31, 32) that alpha-beta search is inherently superior in these domains.

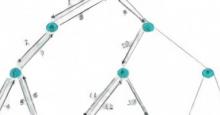
Fig. 4AlphaZero’s search procedure.
The search is illustrated for a position (inset) from game 1 (table S6) between AlphaZero (white) and Stockfish (black) after 29. ... Qf8. The internal state of AlphaZero’s MCTS is summarized after 102, ..., 106 simulations. Each summary shows the 10 most visited states. The estimated value is shown in each state, from white’s perspective, scaled to the range [0, 100]. The visit count of each state, relative to the root state of that tree, is proportional to the thickness of the border circle. AlphaZero considers 30. c6 but eventually plays 30. d5.
The game of chess represented the pinnacle of artificial intelligence research over several decades. State-of-the-art programs are based on powerful engines that search many millions of positions, leveraging handcrafted domain expertise and sophisticated domain adaptations. AlphaZero is a generic reinforcement learning and search algorithm—originally devised for the game of Go—that achieved superior results within a few hours, searching  as many positions, given no domain knowledge except the rules of chess. Furthermore, the same algorithm was applied without modification to the more challenging game of shogi, again outperforming state-of-the-art programs within a few hours. These results bring us a step closer to fulfilling a longstanding ambition of artificial intelligence (3): a general game-playing system that can learn to master any game.
as many positions, given no domain knowledge except the rules of chess. Furthermore, the same algorithm was applied without modification to the more challenging game of shogi, again outperforming state-of-the-art programs within a few hours. These results bring us a step closer to fulfilling a longstanding ambition of artificial intelligence (3): a general game-playing system that can learn to master any game.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
I had a really urgent problem in the middle of the summer that I needed to get fixed. I tried contacting a bunch of agencies but they were either unavailable, slow, had terrible service or were crazy expensive (one company quoted me 1000€!). Josep replied to me within 10 minutes and managed to submit my forms on the deadline and all for a great price. He saved my life - 100% recommend!